What Are the Different Types of Databases?

Databases are an essential part of the Information Technology (IT) age. Choosing the right database systems can be a daunting task with so many types of databases and database management systems.
Before choosing any database system for your business, you must identify your database needs. Do you need CRM database software to store your CRM database properly? Do you need a commercial or personal database?
This article will give you a detailed overview of the various types of databases.
Let’s get started.
What are Databases?
Databases are collections of information stored on digital devices, including mobile phones, digital watches, electronic tablets, and computers.
You can use databases to store files, pictures, audios, and visuals, register details to complete online purchases, analyze the stock market, and access cloud files or documents.
Not only can you store it, but whatever is in the record can easily be accessed, retrieved, and downloaded, as the case may be.
Since the introduction of the database technology, significant improvement has been recorded in the digital space. We now have different types of databases which are categorized based on strengths and weaknesses.
Individuals, especially businesses, should be able to identify and understand the different types, and elements of a database, note their pros and cons, ensure they have the most efficient setup, and understand how to use them.
You cannot understand the concept of databases without knowing these two terms: database schema and data stores. A database schema refers to the overall design and model of data structures. Data stores are database systems that store the data collection, not limited to databases.
Four types of database objects exist for data compilation, entry, storage, and analysis.
- Tables
- Queries
- Forms
- Reports
Types of Databases
The classification of databases depends on several factors, such as how they organize data and manage the database structure. There are thirteen different types of databases.
1. Centralized Database
A centralized database is a type of database that operates entirely from a single set-up or location. You can locate the centralized database on a computer that serves as the central database management system.
The central computer system runs, manages, and maintains the database, but multiple users can access the database through any computer network. Such databases are used in big organizations such as large-scale business ventures or universities.
In the case of a university, the database is run from a single location. Every other authorized user physically absent from that building can access the data represented in the centralized database through a network.
Multiple users can access centralized database management systems through several applications in different locations. These applications will require an authentication process to ensure data security.
A centralized database can be a central library that houses the database of every library in a college or university.

Pros
- Reduced risk of data management
- Central management of data ensures data consistency
- Better data quality raises the standards for organizations
- Lower human labor which translates to fewer costs
Cons
- Large sizes increase the response time for data retrieval
- Difficult to update
- Server failure can lead to huge data loss
2. Commercial Database
This type of database is designed and used by commercial businesses. Businesses establish extensive and full-featured databases with key-value stores, which they sell to customers.
They vary depending on the type of technology used, and their unique trait is that users have to pay before gaining access.
A commercial database is specific to a subject and provided through commercial links. They are paid versions specifically for users that want to access information for help or inquiry.

Pros
- A single point of contact for any problems or issues.
- An extensive and defined development plan for a software
- Licensing and usage requirements
Cons
- Risk of software licensing waste
- Stiff licensing guidelines
- No guarantee of the performance of any software
- Proprietary source code
3. End-user Database
An end-user database is a type of database used by a single person. End-user in product development refers to the product's consumer or the person who uses the product.
A very good example of an end-user database is a spreadsheet stored on a digital device, especially a computer.
Often, the consumer is unaware of the transactional operations at various levels but is only concerned about the product, which may be a product or software application.
Pros
- More accessible to users
- Faster implementation cycle
- Reduction of backlogs
- Reduced communication problems
Cons
- Duplication leads to the waste of resources
- Loss of quality and control over data
- Increased costs
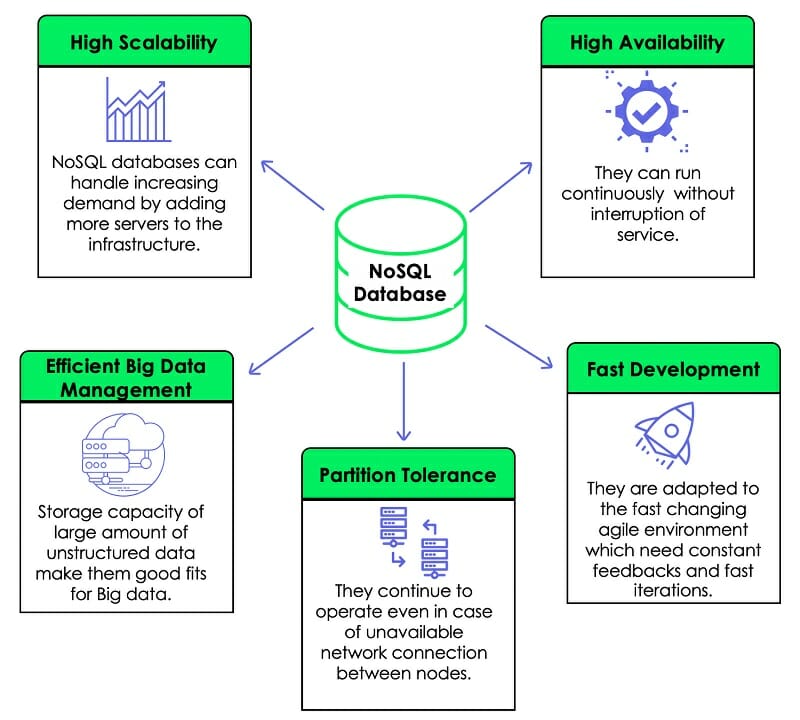
4. NoSQL Database
NoSQL database is similar to a folder system where the data in the files are unstructured and unarranged. The lack of data structure allows users to process large volumes of data at an insanely great speed.
Another benefit of NoSQL databases is that they allow for future expansion because a lack of data structures means no restrictions. Cloud computing regularly employs the concept of NoSQL databases.
NoSQL (Not Only Structured Query Language) database is non-relational because it stores data in several ways. The NoSQL database came around when the demands for modern apps increased.
There are four types of NoSQL databases:
- Wide Column Stores: This database stores and manages huge amounts of data in multiple tables or columns. Another name is a multi-dimensional key-value store. Examples of wide column stores include Scylla, Cassandra, and HBase.
- Graph Databases: This database system focuses on the data and their various connections. It uses graphs to map, analyze, and store relationships.
- Document Databases: In document stores, there is no uniform structure. There can be nested forms and have a multitude of values and types.
- Key-value storage: This database is the simplest NoSQL database to understand. Key-value storage stores all data elements in the database as a key value pair: having a key or attribute name and a value.
Pros
- Productivity in app development
- Easy access to data through key-value
- High scalability
- The best option for managing large data sets
- Rapid development cycles
Cons
- No data backup solution
- Lack of standardization
- Technology still maturing
- Consistency is below average
5. Open-Source Database
Open-source databases are designed for the public to use at no cost. The database system is self-explanatory, even from the name.
Users can sign up on open-source databases without paying a dime, unlike commercial databases, which require some form of payment. You can see how the program is written and constructed and make their desired changes to the program where necessary.
The conditions of use make it evident that open-source databases are cheaper than commercial databases. However, open-source databases do not have as many advanced features as commercial databases.
Pros
- Cost-effective and reliable
- Flexible and scalable
- Error-free and has convenient licensing schemes
Cons
- The graphical UI is not user-friendly
- Compatibility issues with some applications
- The ‘open-source’ feature reduces the security measures
- Hidden maintenance costs
6. Personal Database
Data stored on a personal computer system is the perfect example of a personal database. It is for a single person's use, stored on a simple computer, and has less complicated designs.
Due to its design and modifications, it can not carry out complex business operations and can not be used to store large sets of data. The data stored on personal computers are easily accessible and manageable because of their size.
A personal database is often used by people of the same department in an organization or by a small group of people with common interests.

Pros
- Easy data management
- Small storage space due to small size
- Higher security
Cons
- Few amounts of data
- No external connectivity
7. Cloud Database
A cloud database is run over the internet, unlike databases that are found on local computers. Although the data is stored on local servers or hard drives, the information is available online.
Many businesses store extensive data over a virtual environment (on the cloud). Cloud databases are automated databases for such a virtualized environment.
The availability mode makes it easier for anyone to access information from anywhere on any device as long as there is an active internet connection.
People who use cloud databases either build one themselves or pay an online provider to store their data.

You need to encrypt information on cloud databases to ensure the maximum safety of data. Users use computing services like SaaS, PaaS, and IaaS for accessing data.
Examples of the best cloud platforms are:
- ScienceSoft
- Microsoft Azure
- Amazon Web Services (AWS)
- PhoenixNAP
- Google Cloud SQL
Pros
- Data recovery upon loss
- Easily accessible
- Scalability
- Low costs
- Data protection
Cons
- Compulsory internet connection
- Migration issues
- Fixed contracts
- Lack of maximum control
8. Distributed Database
Unlike the centralized database, the distributed database is spread across different devices.
Instead of converging all the information on a single device, it distributes them across multiple devices in the same location or under the same network. The multiple devices can connect via communication links which will help users to access information easily.

Distributed databases can be divided into two:
- Homogenous Distributed Database: This distributed database uses the same application processes, carries the same hardware components, and is executed over the same operating systems. A homogenous DDB can either be autonomous or non-autonomous.
- Heterogeneous Distributed Database: This database system is processed under different application procedures, executed on different operating systems, and carried on different hardware devices. You can further divide it into federated or multi-database.
Pros
- Server failure does not wipe out the entire data set
- Modular development is available
- Better response system
- Reliability
Cons
- Improper data distribution
- Costly software
- Replication hinders integrity
9. Graph Database
Graph databases focus on the data and the various connections between them. For graph databases, the data is not restricted to predefined models.
Unlike other databases, where connections are found between data in a search, the connections are stored in the database alongside the original data.
You get a faster and more efficient database when connections are managed alongside the data. The graph contains a series of nodes and edges where each point represents an entity while the edges describe the interrelationship between the entities.
A graph database uses graphs to map, analyze, and store relationships. For example, you can use a graph theory to analyze a person that regularly visits an eatery in a particular city.
You can study the person’s reviews of the eatery and city, the address of the eatery in the city, and the address of the person’s house in the city.

Pros
- Flexible structures
- Real-time results
- Lucid representation of relationships
- Query speed is dependent on concrete relationships.
Cons
- Disuniform query language
- The one-tier architectural design makes it difficult to scale
10. Object-Oriented Database
In object-oriented databases, data is represented in objects and classes. Objects could be an item, a name, or a phone number, while a class can identify as a group of objects.
An example of a relational database is the object-oriented database. The best use for object-oriented databases is when you want to process many sophisticated data sets quickly.
Objects representing the data are similar to the ones used in an object-oriented programming language. Object-oriented databases are based on data and objects rather than logic and actions. For example, an audio-visual record can be a definable data object.

Pros
- An object-oriented database supports easy retrieval of complex data sets
- Automatic distribution of object IDs
- Works perfectly with object-oriented programming languages like Java, C++
Cons
- Object-oriented databases are not universally adopted
- Complex data sets may affect performance
11. Operational Database
The operational database falls under the category of databases that lets users tweak or modify data in real-time. This database is essential in warehousing operations and business analytics.
Depending on the needs or requirements, they can be sorted out as relational databases or not only SQL databases (NoSQL).
Unlike conventional databases, the operational database allows you to add, remove, or edit data at any time.
Operational databases are good for handling and managing day-to-day operations in several businesses.
For example, it is perfect for organizations that keep daily records at the end of official work hours. Operational databases help functional document concepts like customer relationships, marketing, and employee welfare.
Pros
- Versatility
- Adaptability
- Fault-tolerant
- High-level security
Cons
- Security issues for data stored in remote locations
- Difficult installation process
12. Relational Database
A relational database houses other major types of databases that are the opposite of NoSQL databases. Information is well structured and arranged in relational databases. It is based on the relational data model.
All information in relational databases has a relationship with each other because every data value has a unique identity calla ed record. The best scenario where relational databases work well is when you care more about your data integrity than scalability.
One good example of relational databases is the relationship between an online shopping customer and their shopping cart.
The relational model uses tables that relate to one another using two critical columns: primary key and foreign key. Relational databases focus on a model that stores data in rows and columns, collectively forming a table.
A relational database uses SQL to maintain, manipulate, and store data. An example of a relational database management system is Microsoft SQL Server.

There are four common properties of relational databases.
- Atomicity: This feature takes the ‘all or nothing’ strategy; every data operation will be completed regardless of its outcome. Atomicity means no neutral stance; it is either success or failure.
- Consistency: The value of data before and after every operation should remain the same. For instance, the account statement before and after transactions should resonate.
- Isolation: Data in relational databases should remain isolated because you have concurrent users accessing the database from different locations. When there are multiple operations, the after-effect of one does not affect other operations in the database.
- Durability: Durability ensures that after every operation, the state of data sets remains permanent.
Pros
- Speed and accuracy
- Security
- Simplicity
- Accessibility
- Multi-user feature
- Easy modification of database entries
Cons
- Complexity
- High costs
- Physical storage
- Information loss
13. Hierarchical Database
Hierarchical databases store information in a tree-like structure using the parent-child relationship and node connections.
Data is stored in the form of records that are interconnected with links. Every child record in the tree will only connect to one parent, while the parent record can be linked to several child records. All XML or JSON documents use a hierarchical data model.
The information in a hierarchical database can follow a progression characterized by levels or ranks depending on the concept in which it is being used.
Hierarchical databases explain that the common linkage between two entities will be an entity higher in rank directly above the two lower entities.
Pros
- Tree-like structure
- Accessibility
- Large base
- Data security
Cons
- Data duplicity
- Stuff rules
- Lack of data independence
- Implementation problems
14. Network Database
Network databases are similar to hierarchical databases due to having a hierarchical structure, but there is a major difference.
Unlike in a hierarchical database where a child entity can only be linked to one parent, multiple child records can link to multiple parent records in a network data model. Due to that, you often see a network of data entities linked with multiple threads in network databases.
Network databases are like graph databases considering the multiple interrelationships. However, it supports multiple relationships instead of adopting a single-parent tree relationship. With a network database, you can have more than one parent for your child's records.
If a hierarchical database can be likened to a chain, then a network database can be called a web because of the complex linkages.
Pros
- Freedom to handle multiple relationships
- Conceptual simplicity
- Data independence
- Easy data access
Cons
- No structural independence
- Operation anomalies
- Network complexity
Was This Article Helpful?
Martin Luenendonk
Martin loves entrepreneurship and has helped dozens of entrepreneurs by validating the business idea, finding scalable customer acquisition channels, and building a data-driven organization. During his time working in investment banking, tech startups, and industry-leading companies he gained extensive knowledge in using different software tools to optimize business processes.
This insights and his love for researching SaaS products enables him to provide in-depth, fact-based software reviews to enable software buyers make better decisions.